import torch
import torch.nn as nn
from transformers import AutoTokenizer
from datasets import load_dataset
import math
from einops import rearrange # einstein operationLlama2 Architecture (P2)
 ”
”
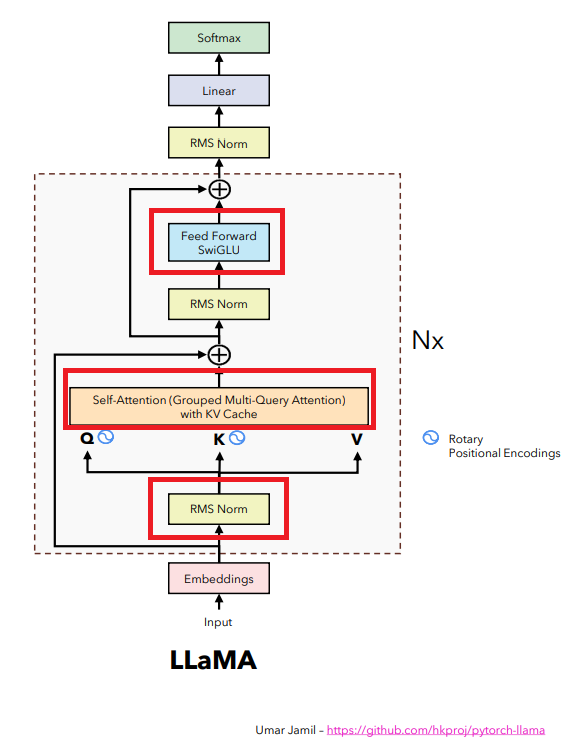
Trong chương này, chúng ta sẽ cùng tìm hiểu về 3 chi tiết còn lại: RMS Norm, Group Multi Query Attention with KV cache, và Feed Forward SwiGLU. Hãy cùng khám phá những khái niệm mới này và tìm hiểu cách chúng hoạt động!
sample = 20
dataset = load_dataset("roneneldan/TinyStories")
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-125M")
tokenizer.pad_token = tokenizer.eos_token
subset_dataset = dataset['train'][:sample]['text']
tokenized_dataset = tokenizer(
subset_dataset,
return_tensors='pt',
padding=True, # Enable padding
truncation=True # Enable truncation
)
data = tokenized_dataset['input_ids']
data.shapeRepo card metadata block was not found. Setting CardData to empty.torch.Size([20, 219])class ModelArgs:
def __init__(self, sequence_len, vocab_size):
self.rotary_dim = 3
self.n_layer = 2
self.batch_size = 16
self.n_head = 4
self.n_embd = 36
self.sequence_len = sequence_len
self.vocab_size = vocab_size
sequence_len = data.size(1) - 1
vocab_size = tokenizer.vocab_size
args = ModelArgs(sequence_len, vocab_size)def get_batch(data, batch_size):
idx = torch.randint(0, len(data), size=(batch_size,))
batch = data[idx]
xb = batch[:, :-1].contiguous()
yb = batch[:, 1:].contiguous()
return xb, yb
xb, yb = get_batch(data, args.batch_size)
xb.shape, yb.shape(torch.Size([16, 218]), torch.Size([16, 218]))Embedding
 ”
”
class Embedding(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
self.wte = nn.Embedding(args.vocab_size, args.n_embd)
def forward(self, input_ids):
input_ids_embd = self.wte(input_ids)
return input_ids_embd
embd = Embedding(args)
x_embd = embd(xb)
x_embd.shapetorch.Size([16, 218, 36])Rotary Embedding
 ”
”
class RotaryPositionEmbedding(nn.Module):
def __init__(self, args:ModelArgs, base = 10000):
super().__init__()
self.rotary_dim = args.rotary_dim
inv_freq = 1.0 / (base ** (torch.arange(0, self.rotary_dim, 2) / self.rotary_dim ))
self.register_buffer("inv_freq", inv_freq)
self.cos_cache = None
self.sin_cache = None
def forward(self, qkv):
seqlen = qkv.shape[1]
# Update cos sin cache
t = torch.arange(seqlen)
freqs = torch.outer(t, self.inv_freq)
self.cos_cache = torch.cos(freqs)
self.sin_cache = torch.sin(freqs)
# Apply rotary qkv
rotary_dim = self.cos_cache.shape[1]
rotary_dim *= 2
q_rot = qkv[:, :, 0, :, :rotary_dim]
q_pass = qkv[:, :, 0, :, rotary_dim:]
k_rot = qkv[:, :, 1, :, :rotary_dim]
k_pass = qkv[:, :, 1, :, rotary_dim:]
# Splits the queries and keys in half
q1, q2 = q_rot.chunk(2, dim=-1)
k1, k2 = k_rot.chunk(2, dim=-1)
c, s = rearrange(self.cos_cache, "t d -> t 1 d"), rearrange(self.sin_cache, "t d -> t 1 d")
# Computes the new keys and queries
q_rot = torch.cat([q1 * c - q2 * s, q1 * s - q2 * c], dim=-1)
k_rot = torch.cat([k1 * c - k2 * s, k1 * s - k2 * c], dim = -1)
return torch.cat(
[
torch.cat([q_rot, q_pass], dim=-1).unsqueeze(2),
torch.cat([k_rot, k_pass], dim=-1).unsqueeze(2),
qkv[:, :, 2:3, :, :]
],
dim=2
)RMS Norm
 ”
”
class RMSNorm(torch.nn.Module):
def __init__(self, dim: int, eps: float = 1e-6):
super().__init__()
self.eps = eps
self.weight = nn.Parameter(torch.ones(dim))
def _norm(self, x):
return x * torch.rsqrt(x.pow(2).mean(-1, keepdim=True) + self.eps)
def forward(self, x):
output = self._norm(x.float()).type_as(x)
return output * self.weight
attn_norm = RMSNorm(args.n_embd)
x_embd_norm = attn_norm(x_embd)
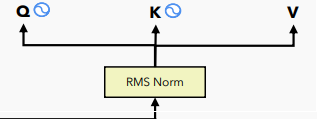
x_embd_norm.shapetorch.Size([16, 218, 36])RMS Norm thực chất là một biến thể của Layer Norm. Ý tưởng cơ bản là thay vì sử dụng Layer Norm làm quá trình normalize dữ liệu, họ chuyển sang sử dụng RMS Norm. Cụ thể, trong ảnh trên thay vì áp dụng layer norm cho x_embd để tính toán qkv, họ thay thế nó bằng RMS Norm. Điều này cũng áp dụng tương tự cho việc normalize output. Sự thay đổi này có thể mang lại một số ưu điểm cụ thể trong quá trình xử lý và huấn luyện mô hình.
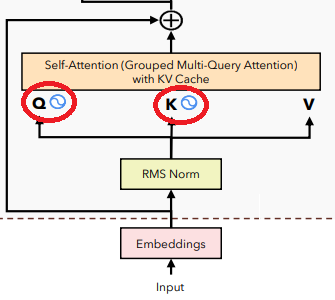
Self Attention
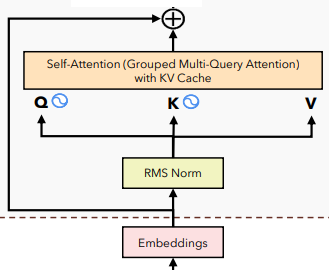 ”
”
import torch.nn.functional as F
class Attention(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
self.rotary_emb = RotaryPositionEmbedding(args)
self.head_dim = args.n_embd // args.n_head
opt_size = args.n_head * self.head_dim
hidden_size = args.n_embd
self.Wqkv = nn.Linear(hidden_size, 3 * opt_size)
self.out_proj = nn.Linear(opt_size, hidden_size)
def forward(self, input_ids_embd_norm):
seq_len = input_ids_embd_norm.shape[1]
qkv = self.Wqkv(input_ids_embd_norm)
qkv = rearrange(qkv, 'b t (three h d) -> b t three h d', three=3, d=self.head_dim)
# Rotary Query & Key
qkv = self.rotary_emb(qkv)
q, k, v = qkv.unbind(2)
# New code
# --------------------------------------------------------------------------------
output = F.scaled_dot_product_attention(q, k, v, is_causal=True)
# softmax_scale = 1.0 / math.sqrt(q.shape[-1])
# scores = torch.einsum("bthd, bshd -> bhts", q, k * softmax_scale)
# mask = torch.triu(torch.full((seq_len, seq_len), -10000), 1)
# scores += mask
# attention_weights = torch.softmax(scores, dim=-1)
# output = torch.einsum("bhts, bshd -> bthd", attention_weights, v)
# ----------------------------------------------------------------------------------
output = rearrange(output, "... h d -> ... (h d)")
attn_out = self.out_proj(output)
return attn_out
# Normalize
attn_norm = RMSNorm(args.n_embd)
x_embd_norm = attn_norm(x_embd)
attn = Attention(args)
attn_out = attn(x_embd_norm)
# add residual
attn_out += x_embd
attn_out.shapetorch.Size([16, 218, 36])Trong phương pháp trước đây, việc tính toán lại các scores một cách lặp đi lặp lại dẫn đến sự lãng phí đáng kể về hiệu suất tính toán. Ví dụ, trong câu “Tôi thích chạy bộ” khi chúng ta cố gắng dự đoán từ “thích” dựa trên từ “Tôi”, chúng ta thực hiện tính scores bằng cách nhân toàn bộ query của từ cần dự đoán với toàn bộ key của các từ khác, sau đó phải loại bỏ scores của các từ không cần thiết (trong trường hợp này là “thích chạy bộ”). Tương tự, khi dự đoán từ “chạy”, chúng ta lại thực hiện lại quá trình tính scores bằng cách nhân toàn bộ query với các key, sau đó phải loại bỏ scores của các từ không cần thiết (“chạy bộ”). Điều này dẫn đến một sự lãng phí lớn về hiệu suất tính toán.
Ý tưởng chính của phương pháp “Group Multi-Query Attention with KV cache” là giảm thiểu sự lãng phí này bằng cách tận dụng lại các kết quả đã được tính toán và lưu trữ trước đó thay vì tính toán lại từ đầu. Hàm F.scaled_dot_product_attention thực hiện ý tưởng này và đồng thời giúp mã nguồn trở nên rõ ràng hơn đáng kể. Sử dụng cách tiếp cận này giúp chúng ta tái sử dụng các kết quả trước đó đã được tính toán và lưu trữ, từ đó giảm thiểu việc tính toán lại và giúp mã nguồn trở nên dễ đọc và dễ hiểu hơn rất nhiều.
Feed Forward
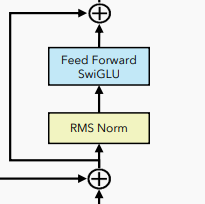 ”
”
class FeedForward(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
multiple_of = 5
hidden_dim = 4 * args.n_embd
hidden_dim = int(2 * hidden_dim / 3)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = nn.Linear(args.n_embd, hidden_dim, bias=False)
self.w2 = nn.Linear(hidden_dim, args.n_embd, bias=False)
self.w3 = nn.Linear(args.n_embd, hidden_dim, bias=False)
self.act = nn.SiLU()
def forward(self, attn_out_norm):
hidden_states = self.w1(attn_out_norm) * self.w3(attn_out_norm)
hidden_states = self.act(hidden_states)
ffwd_out = self.w2(hidden_states)
return ffwd_out
# Normalize
ffwd_norm = RMSNorm(args.n_embd)
attn_out_norm = ffwd_norm(attn_out)
ffwd = FeedForward(args)
ffwd_out = ffwd(attn_out_norm)
# add residual
ffwd_out += attn_out
ffwd_out.shapetorch.Size([16, 218, 36])Giống như trước đó, chúng ta sẽ sử dụng RMS Norm để normalize output attention thay vì Layer Norm.
Feed Forward SwiGLU là một cải tiến của phương pháp Feed Forward thông thường, nhằm tăng cường khả năng học và biểu diễn của mô hình. Bằng cách tăng cường phức tạp hóa cấu trúc của lớp feed forward, SwiGLU có thể học được các mối quan hệ phức tạp và đặc trưng của dữ liệu một cách hiệu quả hơn. Việc tăng cường tính phức tạp của kiến trúc này thường đi kèm với việc sử dụng các phép tính toán và hàm activation phức tạp hơn (SiLU), nhằm tăng tính linh hoạt và mạnh mẽ của mô hình trong việc xử lý dữ liệu phức tạp và đa dạng.
Transformer Block
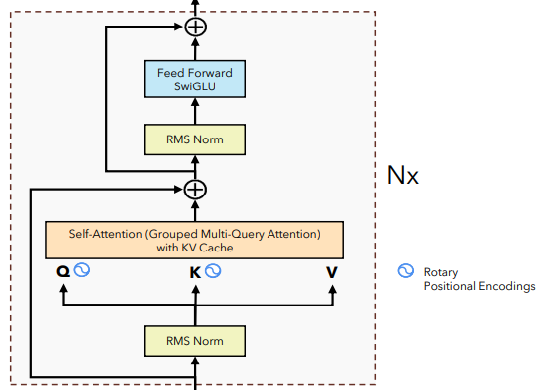 ”
”
class TransfomerBlock(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
self.attention_norm = RMSNorm(args.n_embd)
self.ffwd_norm = RMSNorm(args.n_embd)
self.attn = Attention(args)
self.ffwd = FeedForward(args)
def forward(self, input_ids_embd):
attn_out = input_ids_embd + self.attn(self.attention_norm(input_ids_embd))
ffwd_out = attn_out + self.ffwd(self.ffwd_norm(attn_out))
return ffwd_out
t_block = TransfomerBlock(args)
ffwd_out = t_block(x_embd)
ffwd_out.shapetorch.Size([16, 218, 36])LLAMA2 architecture có những cải tiến hơn so với transformer architecture mà chúng ta đã học trước đó. Các cải tiến này chủ yếu tập trung vào các class Attention và Feed Forward. Do đó, các class còn lại cơ bản chỉ thay đổi việc sử dụng normalize từ Layer Norm sang RMS Norm, các code khác đều sẽ được giữ nguyên.
Transformer
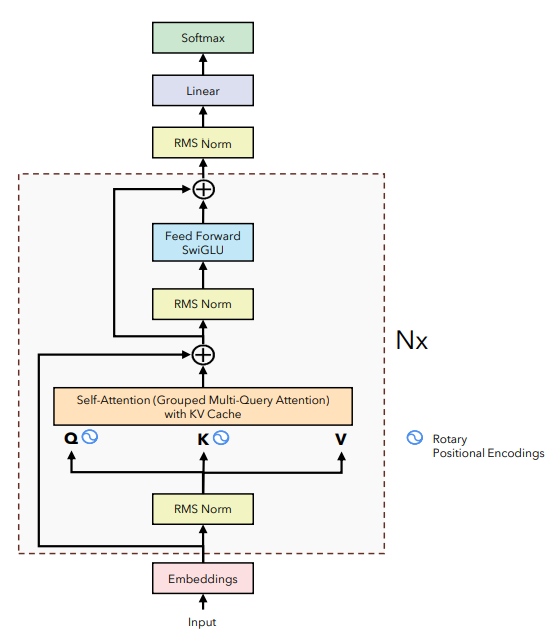
class TransformerHead(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
self.norm = RMSNorm(args.n_embd)
self.linear = nn.Linear(args.n_embd, args.vocab_size)
def forward(self, ffwd_out):
ffwd_out_norm = self.norm(ffwd_out)
logits = self.linear(ffwd_out_norm)
return logits
t_head = TransformerHead(args)
logits = t_head(ffwd_out)
logits.shapetorch.Size([16, 218, 50257])class TransformerSequential(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
modules = [Embedding(args)]
modules += [TransfomerBlock(args) for _ in range(args.n_layer)]
modules.append(TransformerHead(args))
self.layers = nn.Sequential(*modules)
def forward(self, input_ids):
return self.layers(input_ids)
model = TransformerSequential(args)
logits = model(xb)
logits.shapetorch.Size([16, 218, 50257])Loss
class TransformerLoss(nn.Module):
def __init__(self):
super().__init__()
self.loss_fct = nn.CrossEntropyLoss()
def forward(self, logits, labels):
logits = logits.view(-1, logits.shape[-1])
labels = labels.view(-1)
loss = self.loss_fct(logits, labels)
return loss
t_loss = TransformerLoss()
loss = t_loss(logits, yb)
losstensor(10.8817, grad_fn=<NllLossBackward0>)data = tokenized_dataset['input_ids']
sequence_len = data.size(1) - 1
vocab_size = tokenizer.vocab_size
args = ModelArgs(sequence_len, vocab_size)
xb, yb = get_batch(data, args.batch_size)
model = TransformerSequential(args)
logits = model(xb)
t_loss = TransformerLoss()
loss = t_loss(logits, yb)
losstensor(11.0817, grad_fn=<NllLossBackward0>)Vậy là chúng ta đã hoàn thành kiến trúc transformer của LLAMA2.Trong chương tiếp theo, chúng ta sẽ đào sâu vào việc khởi tạo trọng số (weight initialization). Có vẻ như phương pháp khởi tạo trọng số mặc định của PyTorch không còn phù hợp nữa, và LLAMA2 đã sử dụng một phương pháp khởi tạo trọng số khác. Hãy cùng tìm hiểu về điều này trong chương tiếp theo.