import torch
import torch.nn as nn
import torch.nn.functional as F
import matplotlib.pyplot as pltTransformer Architecture
The Goal
Trong chương này, mục tiêu hàng đầu của chúng ta là khám phá một cách chi tiết và cụ thể từng bước của quá trình giải mã (decoder) (phần được khoanh đỏ) dựa trên kiến trúc Attention, như hình minh họa dưới đây:
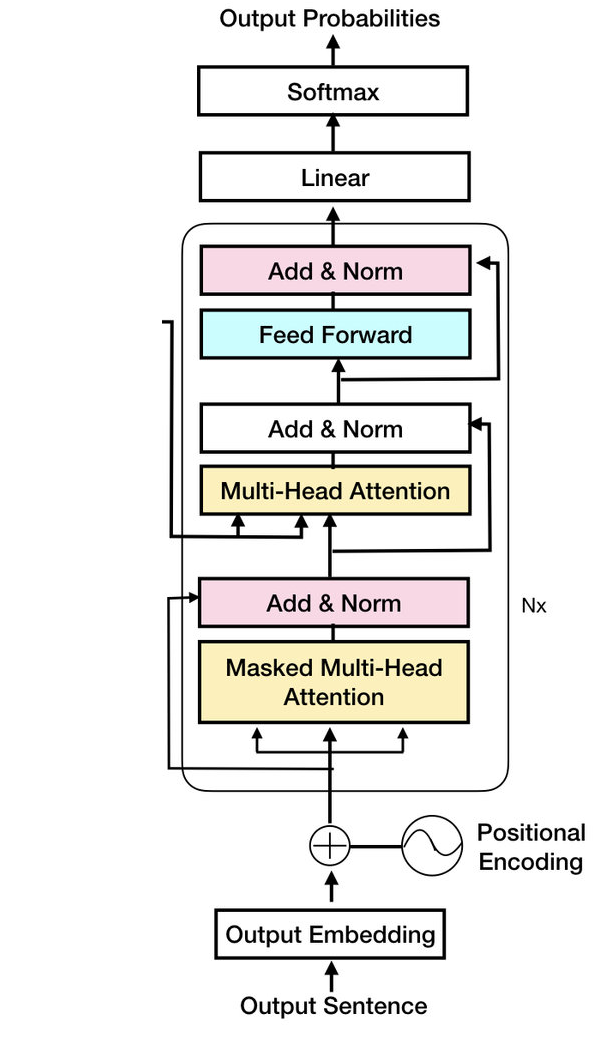
Chúng ta sẽ đảm bảo rằng mỗi bước trong quy trình này được diễn giải một cách chi tiết để chúng ta có thể hiểu sâu hơn về cách nó hoạt động và tương tác với dữ liệu đầu vào. Điều quan trọng là thông qua việc làm này, chúng ta sẽ có cơ hội thấu hiểu rõ hơn về cách áp dụng kiến thức này vào các dự án thực tế, ví dụ như xây dựng một Mô hình Ngôn ngữ Lớn (Large Language Model) cho tiếng Việt, mở ra nhiều tiềm năng ứng dụng hấp dẫn.
Tiny Shakespeare
with open('data/input.txt', 'r', encoding='utf-8') as f:
text = f.read()
print(type(text))
print("length of dataset in characters: ", len(text))<class 'str'>
length of dataset in characters: 1115394Tập dữ liệu “tiny Shakespeare” là một kho văn bản chứa các tác phẩm của danh tác William Shakespeare, với hơn 1 triệu ký tự. Mục tiêu chính của việc sử dụng tập dữ liệu này là xây dựng một mô hình mạng neural có khả năng dự đoán ký tự tiếp theo trong một đoạn văn dựa trên các ký tự trước đó. Mô hình này sẽ có khả năng tái tạo cấu trúc và phong cách viết của Shakespeare, tạo ra văn bản một cách tự nhiên và đầy hấp dẫn.
# let's look at the first 200 characters
print(text[:200])First Citizen:
Before we proceed any further, hear me speak.
All:
Speak, speak.
First Citizen:
You are all resolved rather to die than to famish?
All:
Resolved. resolved.
First Citizen:
First, youProcess Data
# Embedding
chars = sorted(set(text))
print(''.join(chars))
vocab_size = len(chars)
print(vocab_size)
!$&',-.3:;?ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz
65Trong dự án này, chúng ta sẽ sử dụng một phương pháp nhúng (embedding) đơn giản. Cụ thể, chúng ta sẽ xác định tất cả các ký tự duy nhất có trong toàn bộ tập dữ liệu và gán một số duy nhất cho mỗi ký tự này.
Trong tập dữ liệu của chúng ta, có tổng cộng 65 ký tự khác nhau. Mục tiêu chính của dự án là xây dựng một mô hình có khả năng dự đoán ký tự tiếp theo nằm trong 65 ký tự này. Điều này có nghĩa rằng chúng ta muốn mô hình học cách dự đoán ký tự tiếp theo dựa trên ngữ cảnh và phân tích các ký tự trước đó trong chuỗi văn bản.
# Character Encoding
stoi = {s:i for i, s in enumerate(chars)}
itos = {i:s for s, i in stoi.items()}
encode = lambda s: [stoi[c] for c in s]
decode = lambda l: ''.join([itos[i] for i in l])Ở đây, chúng ta đang thực hiện một quá trình được gọi là “mã hóa ký tự (character encoding)”. Trong quá trình này, mỗi ký tự riêng biệt trong dữ liệu của chúng ta sẽ được ánh xạ thành một số nguyên tương ứng. Chúng ta thực hiện việc này để có khả năng chuyển đổi linh hoạt giữa chuỗi ký tự và số nguyên, giúp chúng ta hiểu và biểu diễn kết quả một cách dễ dàng và hiệu quả hơn.
text_exp = "Hello World"
print(encode(text_exp))
print(decode(encode(text_exp)))[20, 43, 50, 50, 53, 1, 35, 53, 56, 50, 42]
Hello World# Convert all text data to integers
data = torch.tensor(encode(text), dtype = torch.long)
data[:16]tensor([18, 47, 56, 57, 58, 1, 15, 47, 58, 47, 64, 43, 52, 10, 0, 14])Chuyển mọi ký tự trong dữ liệu “Tiny Shakespeare” sang số nguyên.
# Define block size and batch size
block_size = 8
batch_size = 4
# Generate random indices within the valid range
ix = torch.randint(0, len(data) - block_size, size=(batch_size,))
# Extract blocks of data using the generated indices
xb = torch.stack([data[i:i+block_size] for i in ix])
# Extract corresponding target blocks
# Note that yb is reshaped to a 1D tensor
yb = torch.stack([data[i+1:i+block_size+1] for i in ix]).view(-1)
# Print the shapes of xb and yb
print("xb.shape:", xb.shape)
print("yb.shape:", yb.shape)xb.shape: torch.Size([4, 8])
yb.shape: torch.Size([32])Bên trên là một ví dụ minh họa về cách tạo x_batch và y_batch sử dụng batch_size, trong đó x_batch được cố định theo block size.
for i in range(block_size):
inp = xb[0, :i+1].tolist()
target = yb[i]
print(f"Input: {inp} --> Target: {target}")Input: [58] --> Target: 46
Input: [58, 46] --> Target: 39
Input: [58, 46, 39] --> Target: 58
Input: [58, 46, 39, 58] --> Target: 1
Input: [58, 46, 39, 58, 1] --> Target: 58
Input: [58, 46, 39, 58, 1, 58] --> Target: 46
Input: [58, 46, 39, 58, 1, 58, 46] --> Target: 43
Input: [58, 46, 39, 58, 1, 58, 46, 43] --> Target: 56Hyperparameters
learning_rate = 1e-3
n_epochs = 1500
vocab_size = len(chars)
n_emb = 32
batch_size = 64
block_size = 8
head_size = 20
n_head = 4Để tránh sự lặp lại không cần thiết trong quá trình giải thích cách thực hiện, chúng ta sẽ duy trì liên tục các biến sau đây.
Distributed Presentation
# Define the embedding size
C = torch.randn(vocab_size, n_emb)
weight = torch.randn(n_emb, vocab_size) * n_emb **-0.5
bias = torch.zeros(vocab_size)
parameters = [C, weight, bias]
num_parameters = 0
for p in parameters:
p.requires_grad = True
num_parameters += p.numel()
print("Total number of trainable parameters:", num_parameters)Total number of trainable parameters: 4225# Forward sample
x_emb = C[xb] # Embedding lookup for input data
print("x_emb.shape:", x_emb.shape)
# Compute logits using a linear transformation
logits = x_emb @ weight + bias
print("logits.shape:", logits.shape)
# Reshape logits for the cross-entropy loss
logits = logits.view(-1, logits.shape[-1])
# Compute the cross-entropy loss
loss = F.cross_entropy(logits, yb)
print("loss:", loss)x_emb.shape: torch.Size([4, 8, 32])
logits.shape: torch.Size([4, 8, 65])
loss: tensor(4.7028, grad_fn=<NllLossBackward0>)optimizer = torch.optim.AdamW(parameters, lr = learning_rate)
for epochi in range(n_epochs):
# Generate random indices within the valid range
ix = torch.randint(0, len(data) - block_size, size=(batch_size,))
# Extract blocks of data using the generated indices
xb = torch.stack([data[i:i+block_size] for i in ix])
# Extract corresponding target blocks
# Note that yb is reshaped to a 1D tensor
yb = torch.stack([data[i+1:i+block_size+1] for i in ix]).view(-1)
x_emb = C[xb] # Embedding lookup for input data
# Compute logits using a linear transformation
logits = x_emb @ weight + bias
# Reshape logits for the cross-entropy loss
logits = logits.view(-1, logits.shape[-1])
# Compute the cross-entropy loss
loss = F.cross_entropy(logits, yb)
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(loss)tensor(2.4565, grad_fn=<NllLossBackward0>)Attention Mechanism
1. Position
C = torch.randn(vocab_size, n_emb)
weight = torch.randn(n_emb, vocab_size) * n_emb **-0.5
bias = torch.zeros(vocab_size)
# New code
# ------------------------------------------------------------
position = torch.randn(block_size, n_emb) * block_size **-0.5
parameters = [C, weight, bias, position]
# ------------------------------------------------------------
num_parameters = 0
for p in parameters:
p.requires_grad = True
num_parameters += p.numel()
print("Total number of trainable parameters:", num_parameters)Total number of trainable parameters: 4481Trong phương pháp “Distributed Presentation,” ban đầu chúng ta đã sử dụng việc nhúng (embedding) để ánh xạ từng từ vào một vector đặc trưng riêng biệt (matrix C). Tuy nhiên, để nâng cao khả năng biểu diễn, chúng ta muốn không chỉ biết về vector đặc trưng (C) của ký tự mà còn quan tâm đến vị trí (position) của ký tự đó trong câu.
Để thực hiện điều này, chúng ta sẽ tạo ra một ma trận vị trí mới (matrix position). Trong ma trận này, mỗi hàng sẽ tương ứng với một vị trí trong câu và nó sẽ được sử dụng để kết hợp với vector đặc trưng (C) của ký tự tại vị trí tương ứng, giúp cải thiện khả năng biểu diễn của mô hình.
def get_batch(data, batch_size, block_size):
# Generate random indices within the valid range
ix = torch.randint(0, len(data) - block_size, size=(batch_size,))
# Extract blocks of data using the generated indices
xb = torch.stack([data[i:i+block_size] for i in ix])
# Extract corresponding target blocks
# Note that yb is reshaped to a 1D tensor
yb = torch.stack([data[i+1:i+block_size+1] for i in ix]).view(-1)
return xb, yb
xb, yb = get_batch(data, batch_size, block_size)
xb.shape, yb.shape(torch.Size([64, 8]), torch.Size([512]))Để tránh việc lặp lại mã code và để tạo sự tiện lợi, tôi tạo một hàm có tên là get_batch để tự động tạo các batch x và y dựa trên kích thước batch_size và block_size.
optimizer = torch.optim.AdamW(parameters, lr = learning_rate)
for i in range(n_epochs):
# New code
# -----------------------------------------------
xb, yb = get_batch(data, batch_size, block_size)
# Embedding lookup for input data
x_emb = C[xb]
x_emb += position
# -----------------------------------------------
# Compute logits using a linear transformation
logits = x_emb @ weight + bias
# Reshape logits for the cross-entropy loss
logits = logits.view(-1, logits.shape[-1])
# Compute the cross-entropy loss
loss = F.cross_entropy(logits, yb)
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(loss)tensor(2.4990, grad_fn=<NllLossBackward0>)2. Weight Average
Hiện tại, mô hình chỉ dựa vào ký tự và vị trí gần nhất của ký tự đó để thực hiện dự đoán. Tuy nhiên, điều này không đủ hiệu quả. Chúng ta muốn mô hình có khả năng sử dụng tất cả thông tin từ các ký tự trước đó để cải thiện dự đoán ký tự tiếp theo.
Hãy xem xét ví dụ từ hai từ “his” và “like.” Giả sử chúng ta cung cấp cho mô hình các vector đặc trưng biểu diễn cho từ “i” và vị trí thứ hai của từ “i” trong câu. Tuy nhiên, trong trường hợp này, mô hình có thể dự đoán ký tự tiếp theo là “s” hoặc “k” mà không có thông tin đủ để quyết định. Điều quan trọng là chúng ta cần cung cấp cho mô hình thông tin về ký tự “h” đứng trước ký tự “i” thay vì “l” để mô hình có thể học được và dự đoán đúng ký tự “s” là ký tự tiếp theo.
# Lower triangular matrix for masking
tril = torch.tril(torch.ones(block_size, block_size))
# Masking to make sure the network can't attend to the future positions
wei = tril.masked_fill(tril==0, float('-inf'))
# Applying softmax to get the attention probabilities
wei = F.softmax(wei, dim=-1)
print(wei)tensor([[1.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.5000, 0.5000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.3333, 0.3333, 0.3333, 0.0000, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2500, 0.2500, 0.2500, 0.2500, 0.0000, 0.0000, 0.0000, 0.0000],
[0.2000, 0.2000, 0.2000, 0.2000, 0.2000, 0.0000, 0.0000, 0.0000],
[0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.1667, 0.0000, 0.0000],
[0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.1429, 0.0000],
[0.1250, 0.1250, 0.1250, 0.1250, 0.1250, 0.1250, 0.1250, 0.1250]])Do đó, chiến lược tạm thời của chúng ta ở đây là tích hợp thông tin từ tất cả các ký tự trước đó, đã xuất hiện, bằng cách tính trung bình của các vector biểu diễn và vị trí của chúng. Điều này sẽ giúp mô hình dự đoán từ tiếp theo một cách chính xác hơn.
C = torch.randn(vocab_size, n_emb)
position = torch.randn(block_size, n_emb)
x_emb = C[xb]
x_emb += position
# New code
# -------------------------------------------------------
# Lower triangular matrix for masking
tril = torch.tril(torch.ones(block_size, block_size))
# Masking to make sure the network can't attend to the future positions
wei = tril.masked_fill(tril==0, float('-inf'))
# Applying softmax to get the attention probabilities
wei = F.softmax(wei, dim=-1)
out = wei @ x_emb
# --------------------------------------------------------
# Print the first 3 elements of the original input and the transformed input for the first block
print(f"Original Input (first batch, first 3 characters):\n {x_emb[0, :3]}")
print("")
print(f"Transformed Input (first batch, first 3 characters):\n {out[0, :3]}")Original Input (first batch, first 3 characters):
tensor([[-0.4335, 0.2487, -1.6515, 2.6138, 0.4584, 1.0921, -1.7675, -0.7268,
2.0422, 2.2848, 0.9093, 0.6099, 1.3877, -0.3385, -3.3128, -0.5631,
-0.7516, 0.2281, -0.5588, 1.6799, -0.8824, 0.6582, 0.7420, -0.1393,
-1.3523, -0.5295, 0.8053, -1.7366, -0.1735, -0.6012, -1.0308, -1.0555],
[-1.0184, -2.0927, -0.3102, 3.6519, -2.4072, 0.0139, 0.9342, -1.7704,
-0.1125, -0.5072, -1.2626, -1.7496, -1.1825, 0.0487, -0.9318, 0.1392,
-2.3752, 1.4060, -1.2250, 1.9381, 0.3784, -1.2098, 0.6793, 0.8746,
-0.5673, -3.0030, 1.0940, -1.0829, 0.0083, 2.4880, -0.3996, 2.7292],
[ 0.4108, 0.8699, -1.0485, -3.0167, 0.0901, -0.1466, -0.6756, 0.8492,
0.2072, 1.3359, -0.2287, 1.1866, -1.0809, -1.1253, -0.8090, -1.1819,
-2.4869, -3.1272, 0.2352, 0.4746, 0.2054, -1.5705, -1.3706, -0.6790,
0.5017, -2.9568, 0.0115, -0.3515, 1.4428, -1.3596, -0.5216, 0.8348]])
Transformed Input (first batch, first 3 characters):
tensor([[-0.4335, 0.2487, -1.6515, 2.6138, 0.4584, 1.0921, -1.7675, -0.7268,
2.0422, 2.2848, 0.9093, 0.6099, 1.3877, -0.3385, -3.3128, -0.5631,
-0.7516, 0.2281, -0.5588, 1.6799, -0.8824, 0.6582, 0.7420, -0.1393,
-1.3523, -0.5295, 0.8053, -1.7366, -0.1735, -0.6012, -1.0308, -1.0555],
[-0.7260, -0.9220, -0.9808, 3.1329, -0.9744, 0.5530, -0.4166, -1.2486,
0.9648, 0.8888, -0.1766, -0.5698, 0.1026, -0.1449, -2.1223, -0.2119,
-1.5634, 0.8171, -0.8919, 1.8090, -0.2520, -0.2758, 0.7107, 0.3676,
-0.9598, -1.7663, 0.9496, -1.4098, -0.0826, 0.9434, -0.7152, 0.8369],
[-0.3471, -0.3247, -1.0034, 1.0830, -0.6196, 0.3198, -0.5029, -0.5493,
0.7123, 1.0379, -0.1940, 0.0157, -0.2919, -0.4717, -1.6845, -0.5353,
-1.8712, -0.4977, -0.5162, 1.3642, -0.0995, -0.7074, 0.0169, 0.0187,
-0.4726, -2.1631, 0.6369, -1.0570, 0.4259, 0.1757, -0.6507, 0.8362]])class BigramLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# Embedding layers
self.C = torch.randn(vocab_size, n_emb) * vocab_size ** -0.5
self.position = torch.randn(block_size, n_emb) * block_size **-0.5
# Linear layer for language modeling
self.weight = torch.randn(n_emb, vocab_size) * n_emb **-0.5
self.bias = torch.zeros(vocab_size)
self.parameters = [self.C, self.weight, self.bias, self.position]
for p in self.parameters:
p.requires_grad = True
def forward(self, inp, targets):
# Embedding lookup for input data
x_emb = self.C[inp]
x_emb += position
# New code
# -------------------------------------------------------------
# Lower triangular matrix for masking
tril = torch.tril(torch.ones(block_size, block_size))
# Masking to make sure the network can't attend to the future positions
wei = tril.masked_fill(tril==0, float('-inf'))
# Applying softmax to get the attention probabilities
wei = F.softmax(wei, dim=1)
out = wei @ x_emb
logits = out @ weight + bias
# -------------------------------------------------------------
# Reshape logits for the cross-entropy loss
logits = logits.view(-1, logits.shape[-1])
# Compute the cross-entropy loss
loss = F.cross_entropy(logits, targets)
return logits, loss
model = BigramLanguageModel()
num_parameters = 0
for p in model.parameters:
num_parameters += p.numel()
print("Total number of trainable parameters:", num_parameters)Total number of trainable parameters: 4481optimizer = torch.optim.AdamW(model.parameters, lr = learning_rate)
for i in range(n_epochs):
xb, yb = get_batch(data, batch_size, block_size)
logits, loss = model(xb, yb)
# Backward
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(loss)tensor(3.0674, grad_fn=<NllLossBackward0>)3. Key, Query, Value
Mô hình hiện tại của chúng ta vẫn chưa đủ hiệu quả, vì chúng ta cần xem xét xác suất quan trọng của các từ đã xuất hiện trước đó đối với việc dự đoán ký tự tiếp theo. Hãy xem xét ví dụ với các từ thay vì ký tự, vì tôi nghĩ điều này có thể giúp chúng ta hiểu rõ hơn.
Ví dụ, trong câu “He is a boy,” để dự đoán từ “boy,” các từ “he” và “is” sẽ có đóng góp quan trọng hơn so với từ “a” trong quá trình dự đoán. Điều này có nghĩa là mô hình cần hiểu được sự liên kết ngữ cảnh giữa các từ và xác định xem từ nào có ảnh hưởng lớn đến dự đoán của mình.
# Get a batch of data
xb, yb = get_batch(data, batch_size, block_size)
C = torch.randn(vocab_size, n_emb)
position = torch.randn(block_size, n_emb)
# Embed input data
x_emb = C[xb]
x_emb += position
# New code
# ------------------------------------------------------
# Initialize key and query matrices
key = torch.randn(n_emb, head_size) * n_emb ** -0.5
query = torch.randn(n_emb, head_size) * n_emb ** -0.5
# Calculate the key and query values
k = x_emb @ key
q = x_emb @ query
# Compute the dot product between queries and keys
wei = q @ k.transpose(-2, -1) * k.shape[-1]**-0.5
print(wei.shape)
tril = torch.tril(torch.ones(block_size, block_size))
wei = wei.masked_fill(tril==0, float('-inf'))
# ------------------------------------------------------
wei=F.softmax(wei, dim=-1)
print(wei[0])torch.Size([64, 8, 8])
tensor([[1.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[1.0000e+00, 4.5888e-07, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[2.2766e-02, 9.3893e-01, 3.8305e-02, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[4.0015e-03, 8.9893e-01, 3.7121e-05, 9.7027e-02, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[1.4366e-02, 1.1882e-03, 6.8691e-01, 1.9523e-02, 2.7801e-01, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[1.7339e-15, 1.4864e-16, 9.9915e-01, 8.5241e-04, 5.7747e-15, 1.8133e-14,
0.0000e+00, 0.0000e+00],
[3.1721e-01, 1.3526e-06, 3.7937e-09, 2.6322e-06, 1.0903e-10, 1.1801e-01,
5.6478e-01, 0.0000e+00],
[6.3539e-10, 5.0136e-11, 9.9992e-01, 7.7084e-05, 2.7238e-08, 1.9036e-14,
2.8848e-12, 4.0533e-11]])# New code
# ------------------------------------------------------
value = torch.randn(n_emb, head_size) * n_emb ** -0.5
v = x_emb @ value
out = wei @ v
# ------------------------------------------------------
out.shapetorch.Size([64, 8, 20])Hãy tưởng tượng rằng bạn là một nhà báo nổi tiếng đang thực hiện một cuộc phỏng vấn với một ngôi sao nổi tiếng, và bạn muốn thu thập thông tin quan trọng từ cuộc trò chuyện đó.
Key có thể coi như danh sách câu hỏi bạn chuẩn bị trước cuộc phỏng vấn. Mỗi câu hỏi là một Key, và mỗi câu hỏi sẽ tập trung vào một khía cạnh cụ thể của cuộc trò chuyện. Ví dụ, một Key có thể là “Bạn đã từng giành giải Oscar chưa?”
Value là câu trả lời mà ngôi sao đưa ra cho từng câu hỏi. Mỗi câu trả lời chứa thông tin quan trọng về cuộc trò chuyện, và nó sẽ được lưu trữ và sử dụng sau này khi bạn cần nắm bắt thông tin cụ thể từ cuộc phỏng vấn. Chúng ta có thể coi câu trả lời này là “value” của câu hỏi.
Query là cách bạn đặt câu hỏi hoặc tìm kiếm thông tin trong cuộc phỏng vấn. Khi bạn muốn biết điều gì đó cụ thể hoặc muốn nắm bắt một thông tin quan trọng từ cuộc trò chuyện, bạn sẽ đặt câu hỏi hoặc tạo một “Query” riêng. Ví dụ, “Giới thiệu về những vai diễn nổi bật nhất của bạn?” có thể là một Query.
Khi bạn đặt một câu hỏi (Query), mô hình sẽ so sánh nó với danh sách các câu hỏi trước đó (Key) và quyết định câu trả lời nào (Value) chứa thông tin phù hợp nhất với câu hỏi của bạn. Điều này giống như việc bạn tập trung vào câu hỏi cụ thể nào trong cuộc trò chuyện để thu thập thông tin bạn cần.
class FeedFoward(nn.Module):
def __init__(self, n_emb):
super().__init__()
self.weight1 = torch.randn(n_emb, 3 * n_emb) * n_emb ** -0.5
self.bias1 = torch.zeros(3 * n_emb)
self.weight2 = torch.randn(3 * n_emb, n_emb) * ((3 * n_emb) ** -0.5)
self.bias2 = torch.zeros(n_emb)
self.parameters = [self.weight1, self.bias1, self.weight2, self.bias2]
def forward(self, x):
x = x @ self.weight1 + self.bias1
x = F.relu(x)
out = x @ self.weight2 + self.bias2
return outclass BigramLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# Embedding layers
self.C = torch.randn(vocab_size, n_emb) * vocab_size ** -0.5
self.position = torch.randn(block_size, n_emb) * block_size **-0.5
# Feed-Forward Layer
self.ffwd = FeedFoward(n_emb)
# Linear layer for language modeling
self.lm_head = nn.Linear(n_emb, vocab_size)
# New code
# ---------------------------------------------------------------
self.proj = torch.randn(head_size, n_emb) * head_size ** -0.5
self.key = torch.randn(n_emb, head_size) * n_emb ** -0.5
self.query = torch.randn(n_emb, head_size) * n_emb ** -0.5
self.value = torch.randn(n_emb, head_size) * n_emb ** -0.5
self.parameters = [self.C, self.position, self.key, self.query, \
self.value, self.proj] + self.ffwd.parameters
# ---------------------------------------------------------------
for p in self.parameters:
p.requires_grad = True
def forward(self, inp, targets):
x_emb = self.C[inp] # Embedding lookup for input data
x_emb += position
# New code
# -----------------------------------------------------
k = x_emb @ self.key
q = x_emb @ self.query
# Compute the attention weights
wei = q @ k.transpose(-2, -1) * k.shape[-1]**-0.5
tril = torch.tril(torch.ones(block_size, block_size))
wei = wei.masked_fill(tril==0, float('-inf'))
wei = F.softmax(wei, dim=-1)
v = x_emb @ self.value
out = wei @ v
out = out @ self.proj
# Feed-Forward
out = self.ffwd(out)
# ----------------------------------------------------
# Linear layer for language modeling
logits = self.lm_head(out)
# Reshape logits for the cross-entropy loss
logits = logits.view(-1, logits.shape[-1])
# Compute the cross-entropy loss
loss = F.cross_entropy(logits, targets)
return logits, loss
model = BigramLanguageModel()
num_parameters = 0
for p in model.parameters:
num_parameters += p.numel()
print("Total number of trainable parameters:", num_parameters)Total number of trainable parameters: 11168optimizer = torch.optim.AdamW(model.parameters, lr = learning_rate)
for i in range(n_epochs):
xb, yb = get_batch(data, batch_size, block_size)
logits, loss = model(xb, yb)
# Backward
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(loss)tensor(2.9821, grad_fn=<NllLossBackward0>)4. Layer Norm
class FeedFoward(nn.Module):
def __init__(self, n_emb):
super().__init__()
self.inp = nn.Linear(n_emb, 3 * n_emb)
self.fc1 = nn.Linear(3 * n_emb, n_emb)
def forward(self, x):
x = self.inp(x)
x = F.relu(x)
out = self.fc1(x)
return outclass Head(nn.Module):
def __init__(self, head_size):
super().__init__()
# Linear transformations for key, query, and value
self.key = nn.Linear(n_emb, head_size, bias=False)
self.query = nn.Linear(n_emb, head_size, bias=False)
self.value = nn.Linear(n_emb, head_size, bias=False)
# Lower triangular matrix for masking
self.tril = torch.tril(torch.ones(block_size, block_size))
def forward(self, x):
# Linear transformations for key and query
k = self.key(x)
q = self.query(x)
# Compute the attention weights
wei = q @ k.transpose(-2, -1) * k.shape[-1]**-0.5
wei.masked_fill_(self.tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
# Linear transformation for value and computing the output
v = self.value(x)
out = wei @ v
return outclass BigramLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# Embedding layers
self.C = nn.Embedding(vocab_size, n_emb)
self.position = nn.Embedding(block_size, n_emb)
# Single-Head Attention Layer
self.head = Head(head_size)
self.proj = nn.Linear(head_size, n_emb)
# Feed-Forward Layer
self.ffwd = FeedFoward(n_emb)
# Linear layer for language modeling
self.lm_head = nn.Linear(n_emb, vocab_size)
# New code
# ------------------------------------
# Layer Normalization Layers
self.ln1 = nn.LayerNorm(n_emb)
self.ln2 = nn.LayerNorm(n_emb)
self.ln3 = nn.LayerNorm(n_emb)
# ------------------------------------
def forward(self, inp, targets):
# Embedding lookup for input data
token_emb = self.C(inp)
position_emb = self.position(torch.arange(inp.size(1)))
x_emb = token_emb + position_emb
# New code
# -----------------------------------------------------
# Single-Head Attention
out = self.head(self.ln1(x_emb))
out = self.proj(out)
# Feed-Forward
out = self.ffwd(self.ln2(out))
# Final layer normalization
out = self.ln3(out)
# ----------------------------------------------------
# Linear layer for language modeling
logits = self.lm_head(out)
# Reshape logits for the cross-entropy loss
logits = logits.view(-1, logits.shape[-1])
# Compute the cross-entropy loss
loss = F.cross_entropy(logits, targets)
return logits, loss
model = BigramLanguageModel()
num_parameters = 0
for p in model.parameters():
num_parameters += p.numel()
print("Total number of trainable parameters:", num_parameters)Total number of trainable parameters: 13537optimizer = torch.optim.AdamW(model.parameters(), lr = learning_rate)
for i in range(n_epochs):
xb, yb = get_batch(data, batch_size, block_size)
logits, loss = model(xb, yb)
# Backward
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(loss)tensor(2.2237, grad_fn=<NllLossBackward0>)5. Multi-head Attention
# Get a batch of data
xb, yb = get_batch(data, batch_size, block_size)
C = torch.randn(vocab_size, n_emb)
position = torch.randn(block_size, n_emb)
# Embed input data
x_emb = C[xb]
x_emb += position
# New code
# ----------------------------------------------------------------------
# Initialize key and query matrices
key_list = [torch.randn(n_emb, head_size // n_head) * \
n_emb ** -0.5 for headi in range(n_head)]
query_list = [torch.randn(n_emb, head_size // n_head) * \
n_emb ** -0.5 for headi in range(n_head)]
# Calculate the key and query values
k = torch.stack([x_emb @ key for key in key_list], dim = -1).view\
(xb.shape[0], block_size, -1)
q = torch.stack([x_emb @ query for query in query_list], dim = -1).view\
(xb.shape[0], block_size, -1)
# ----------------------------------------------------------------------
print(k.shape)
print(q.shape)
# Compute the dot product between queries and keys
wei = q @ k.transpose(-2, -1)
print(wei.shape)
tril = torch.tril(torch.ones(block_size, block_size))
wei = wei.masked_fill(tril==0, float('-inf'))
wei = F.softmax(wei, dim=-1)
print(wei[0])torch.Size([64, 8, 20])
torch.Size([64, 8, 20])
torch.Size([64, 8, 8])
tensor([[1.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[2.7624e-02, 9.7238e-01, 0.0000e+00, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[6.3034e-07, 9.9980e-01, 2.0172e-04, 0.0000e+00, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[8.8760e-07, 9.9450e-01, 5.5003e-03, 3.7328e-10, 0.0000e+00, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[6.4108e-01, 2.2718e-05, 4.7551e-02, 3.0472e-01, 6.6321e-03, 0.0000e+00,
0.0000e+00, 0.0000e+00],
[3.5899e-09, 2.0306e-06, 1.2872e-01, 1.9127e-11, 9.4477e-13, 8.7128e-01,
0.0000e+00, 0.0000e+00],
[3.4409e-09, 2.2824e-02, 8.0748e-01, 4.0223e-02, 5.4004e-03, 1.2398e-01,
9.4144e-05, 0.0000e+00],
[1.4672e-07, 9.9970e-01, 3.0362e-04, 2.6681e-13, 2.8710e-12, 1.0302e-06,
2.3637e-08, 2.4413e-09]])# New code
# ----------------------------------------------------------------------
value_list = [torch.randn(n_emb, head_size // n_head) * \
n_emb ** -0.5 for headi in range(n_head)]
v = torch.stack([x_emb @ value for value in value_list], dim = -1).view\
(xb.shape[0], block_size, -1)
# ----------------------------------------------------------------------
print(v.shape)
out = wei @ v
out.shapetorch.Size([64, 8, 20])torch.Size([64, 8, 20])class FeedFoward(nn.Module):
def __init__(self, n_emb):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(n_emb, 3 * n_emb),
nn.ReLU(),
nn.Linear(3 * n_emb, n_emb)
)
def forward(self, x):
return self.layers(x)class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
# Linear transformations for key, query, and value
self.key = nn.Linear(n_emb, head_size, bias=False)
self.query = nn.Linear(n_emb, head_size, bias=False)
self.value = nn.Linear(n_emb, head_size, bias=False)
# Lower triangular matrix for masking
self.tril = torch.tril(torch.ones(block_size, block_size))
def forward(self, x):
# Linear transformations for key and query
k = self.key(x)
q = self.query(x)
# Compute the attention weights
wei = q @ k.transpose(-2, -1) * k.shape[-1]**-0.5
wei.masked_fill_(self.tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
# Linear transformation for value and computing the output
v = self.value(x)
out = wei @ v
return out# New code
# -----------------------------------------------------------------
class MultiHeadAttention(nn.Module):
def __init__(self, n_head, head_size):
super().__init__()
self.head_size = head_size // n_head
self.heads = nn.ModuleList([Head(self.head_size) \
for _ in range(n_head)])
self.proj = nn.Linear(self.head_size * n_head, n_emb)
def forward(self, x):
# Apply all attention heads in parallel
out = torch.cat([head(x) for head in self.heads], dim=-1)
# Project the concatenated results
out = self.proj(out)
return out
# -----------------------------------------------------------------class BigramLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# Embedding layers
self.C = nn.Embedding(vocab_size, n_emb)
self.position = nn.Embedding(block_size, n_emb)
# New code
# -----------------------------------------------------
# Multi-Head Attention Layer
self.mul_head = MultiHeadAttention(n_head, head_size)
# -----------------------------------------------------
# Feed-Forward Layer
self.ffwd = FeedFoward(n_emb)
# Layer Normalization Layers
self.ln1 = nn.LayerNorm(n_emb)
self.ln2 = nn.LayerNorm(n_emb)
# Final layer normalization
self.ln_f = nn.LayerNorm(n_emb)
# Linear layer for language modeling
self.lm_head = nn.Linear(n_emb, vocab_size)
def forward(self, inp, targets):
# Embedding lookup for input data
token_emb = self.C(inp)
position_emb = self.position(torch.arange(inp.size(1)))
x_emb = token_emb + position_emb
# New code
# -----------------------------------------------------
# Multi-Head Attention
out = self.mul_head(self.ln1(x_emb))
# ----------------------------------------------------
# Feed-Forward
out = self.ffwd(self.ln2(out))
# Final layer normalization
out = self.ln_f(out)
# Linear layer for language modeling
logits = self.lm_head(out)
# Reshape logits for the cross-entropy loss
logits = logits.view(-1, logits.shape[-1])
# Compute the cross-entropy loss
loss = F.cross_entropy(logits, targets)
return logits, loss
model = BigramLanguageModel()
num_parameters = 0
for p in model.parameters():
num_parameters += p.numel()
print("Total number of trainable parameters:", num_parameters)Total number of trainable parameters: 13537optimizer = torch.optim.AdamW(model.parameters(), lr = learning_rate)
for i in range(n_epochs):
xb, yb = get_batch(data, batch_size, block_size)
logits, loss = model(xb, yb)
# Backward
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(loss)tensor(2.2155, grad_fn=<NllLossBackward0>)6. Residual
class FeedFoward(nn.Module):
def __init__(self, n_emb):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(n_emb, 3 * n_emb),
nn.ReLU(),
nn.Linear(3 * n_emb, n_emb)
)
def forward(self, x):
return self.layers(x)class Head(nn.Module):
def __init__(self, head_size):
super().__init__()
# Linear transformations for key, query, and value
self.key = nn.Linear(n_emb, head_size, bias=False)
self.query = nn.Linear(n_emb, head_size, bias=False)
self.value = nn.Linear(n_emb, head_size, bias=False)
# Lower triangular matrix for masking
self.tril = torch.tril(torch.ones(block_size, block_size))
def forward(self, x):
# Linear transformations for key and query
k = self.key(x)
q = self.query(x)
# Compute the attention weights
wei = q @ k.transpose(-2, -1) * k.shape[-1]**-0.5
wei.masked_fill_(self.tril == 0, float('-inf'))
wei = F.softmax(wei, dim=-1)
# Linear transformation for value and computing the output
v = self.value(x)
out = wei @ v
return outclass MultiHeadAttention(nn.Module):
def __init__(self, n_head, head_size):
super().__init__()
self.head_size = head_size // n_head
self.heads = nn.ModuleList([Head(self.head_size) \
for _ in range(n_head)])
self.proj = nn.Linear(self.head_size * n_head, n_emb)
def forward(self, x):
# Apply all attention heads in parallel
out = torch.cat([head(x) for head in self.heads], dim=-1)
# Project the concatenated results
out = self.proj(out)
return outclass BigramLanguageModel(nn.Module):
def __init__(self):
super().__init__()
# Embedding layers
self.C = nn.Embedding(vocab_size, n_emb)
self.position = nn.Embedding(block_size, n_emb)
# Multi-Head Attention Layer
self.mul_head = MultiHeadAttention(n_head, head_size)
# Feed-Forward Layer
self.ffwd = FeedFoward(n_emb)
# Layer Normalization Layers
self.ln1 = nn.LayerNorm(n_emb)
self.ln2 = nn.LayerNorm(n_emb)
# Final layer normalization
self.ln_f = nn.LayerNorm(n_emb)
# Linear layer for language modeling
self.lm_head = nn.Linear(n_emb, vocab_size)
def forward(self, inp, targets):
# Embedding lookup for input data
token_emb = self.C(inp)
position_emb = self.position(torch.arange(inp.size(1)))
x_emb = token_emb + position_emb
# New code
# ---------------------------------------------------------
# Multi-Head Attention
out = x_emb + self.mul_head(self.ln1(x_emb))
# Feed-Forward
out = out + self.ffwd(self.ln2(out))
# ---------------------------------------------------------
# Final layer normalization
out = self.ln_f(out)
# Linear layer for language modeling
logits = self.lm_head(out)
# Reshape logits for the cross-entropy loss
logits = logits.view(-1, logits.shape[-1])
# Compute the cross-entropy loss
loss = F.cross_entropy(logits, targets)
return logits, loss
model = BigramLanguageModel()
num_parameters = 0
for p in model.parameters():
num_parameters += p.numel()
print("Total number of trainable parameters:", num_parameters)Total number of trainable parameters: 13537model = BigramLanguageModel()
optimizer = torch.optim.AdamW(model.parameters(), lr = learning_rate)
for i in range(n_epochs):
xb, yb = get_batch(data, batch_size, block_size)
logits, loss = model(xb, yb)
# Backward
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(loss)tensor(2.2127, grad_fn=<NllLossBackward0>)Clean code
class FeedFoward(nn.Module):
def __init__(self, n_emb):
super().__init__()
self.layers = nn.Sequential(
nn.Linear(n_emb, 3 * n_emb),
nn.ReLU(),
nn.Linear(3 * n_emb, n_emb)
)
def forward(self, x):
return self.layers(x)class Head(nn.Module):
def __init__(self, n_emb, block_size, head_size):
super().__init__()
# Linear transformations for key, query, and value
self.key = nn.Linear(n_emb, head_size, bias=False)
self.query = nn.Linear(n_emb, head_size, bias=False)
self.value = nn.Linear(n_emb, head_size, bias=False)
# Lower triangular matrix for masking
self.tril = torch.tril(torch.ones(block_size, block_size))
def forward(self, x):
# Linear transformations for key and query
k = self.key(x)
q = self.query(x)
# Compute the attention weights
wei = q @ k.transpose(-2, -1) * k.shape[-1]**-0.5
# Masking to make sure the network can't attend to the future positions
wei.masked_fill_(self.tril == 0, float('-inf'))
# Applying softmax to get the attention probabilities
wei = F.softmax(wei, dim=-1)
# Linear transformation for value and computing the output
v = self.value(x)
out = wei @ v
return outclass MultiHeadAttention(nn.Module):
def __init__(self, n_emb, n_head, head_size):
super().__init__()
self.head_size = head_size
self.heads = nn.ModuleList([Head(n_emb, block_size, head_size) for _ in range(n_head)])
self.proj = nn.Linear(self.head_size * n_head, n_emb)
def forward(self, x):
# Apply all attention heads in parallel
out = torch.cat([head(x) for head in self.heads], dim=-1)
# Project the concatenated results
out = self.proj(out)
return outclass Block(nn.Module):
def __init__(self, n_emb, n_head):
super().__init__()
head_size = n_emb // n_head
# Multi-Head Attention Layer
self.mul_head = MultiHeadAttention(n_emb, n_head, head_size)
# Feed-Forward Layer
self.ffwd = FeedFoward(n_emb)
# Layer Normalization Layers
self.ln1 = nn.LayerNorm(n_emb)
self.ln2 = nn.LayerNorm(n_emb)
def forward(self, x):
# Multi-Head Attention Block
x = x + self.mul_head(self.ln1(x))
# Feed-Forward Block
x = x + self.ffwd(self.ln2(x))
return xclass BigramLanguageModel(nn.Module):
def __init__(self, vocab_size, n_emb, block_size, n_head, n_layers):
super().__init__()
self.n_layers = n_layers
# Embedding layers
self.C = nn.Embedding(vocab_size, n_emb)
self.position = nn.Embedding(block_size, n_emb)
# Transformer blocks
self.blocks = nn.Sequential(*[Block(n_emb, n_head) for _ in range(n_layers)])
# Final layer normalization
self.ln_f = nn.LayerNorm(n_emb)
# Linear layer for language modeling
self.lm_head = nn.Linear(n_emb, vocab_size)
def forward(self, inp, targets):
# Embedding lookup for input data
token_emb = self.C(inp)
position_emb = self.position(torch.arange(inp.shape[1]))
x_emb = token_emb + position_emb
# Transformer blocks
out = self.blocks(x_emb)
# Final layer normalization
out = self.ln_f(out)
# Linear layer for language modeling
logits = self.lm_head(out)
# Reshape logits for the cross-entropy loss
logits = logits.view(-1, logits.shape[-1])
# Compute the cross-entropy loss
loss = F.cross_entropy(logits, targets)
return logits, lossn_layers = 1
model = BigramLanguageModel(vocab_size, n_emb, block_size, n_head, n_layers)
num_parameters = 0
for p in model.parameters():
num_parameters += p.numel()
print("Total number of trainable parameters:", num_parameters)Total number of trainable parameters: 15073optimizer = torch.optim.AdamW(model.parameters(), lr = learning_rate)
for i in range(n_epochs):
xb, yb = get_batch(data, batch_size, block_size)
logits, loss = model(xb, yb)
# Backward
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(loss)tensor(2.2123, grad_fn=<NllLossBackward0>)