import torch
import torch.nn as nn
from transformers import AutoTokenizer
from datasets import load_dataset
import math
from einops import rearrange # einstein operationLlama2 Architecture (P1)
 ”
”
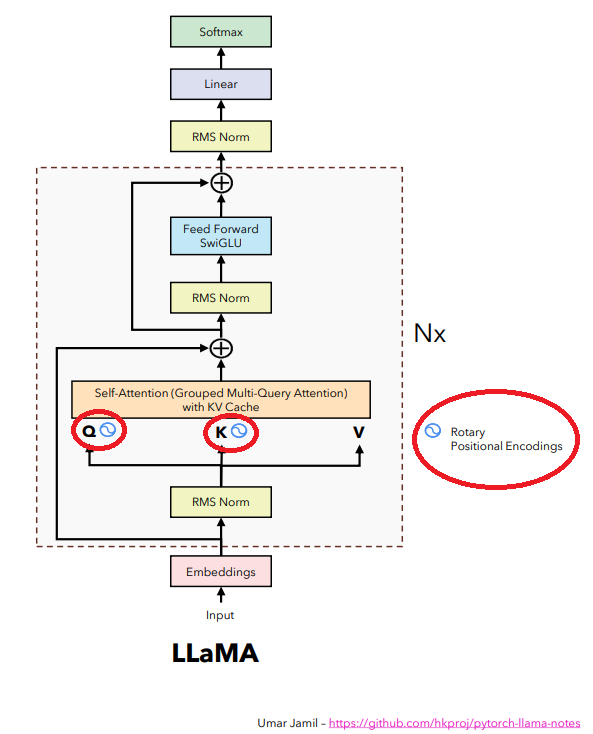
Trong kiến trúc transformers của LLAMA2, có tổng cộng 4 điểm khác biệt chính so với kiến trúc mà chúng ta đã học trước đó. Tuy nhiên, trong chương này, chúng ta sẽ chỉ nói về Rotary Positional Encodings vì có thể chỉ tốn 5 phút nếu bạn chỉ muốn nắm ý tưởng chính của nó, hoặc có thể mất hàng giờ nếu bạn muốn thực sự tìm hiểu sâu hơn về nó.
sample = 20
dataset = load_dataset("roneneldan/TinyStories")
tokenizer = AutoTokenizer.from_pretrained("EleutherAI/gpt-neo-125M")
tokenizer.pad_token = tokenizer.eos_token
subset_dataset = dataset['train'][:sample]['text']
tokenized_dataset = tokenizer(
subset_dataset,
return_tensors='pt',
padding=True, # Enable padding
truncation=True # Enable truncation
)
data = tokenized_dataset['input_ids']
data.shapeRepo card metadata block was not found. Setting CardData to empty.torch.Size([20, 219])class ModelArgs:
def __init__(self, sequence_len, vocab_size):
self.n_layer = 2
self.batch_size = 16
self.n_head = 4
self.n_embd = 36
self.sequence_len = sequence_len
self.vocab_size = vocab_size
sequence_len = data.size(1) - 1
vocab_size = tokenizer.vocab_size
args = ModelArgs(sequence_len, vocab_size)def get_batch(data, batch_size):
idx = torch.randint(0, len(data), size=(batch_size,))
batch = data[idx]
xb = batch[:, :-1].contiguous()
yb = batch[:, 1:].contiguous()
return xb, yb
xb, yb = get_batch(data, args.batch_size)
xb.shape, yb.shape(torch.Size([16, 218]), torch.Size([16, 218]))Embedding
 ”
”
class Embedding(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
self.wte = nn.Embedding(args.vocab_size, args.n_embd)
def forward(self, input_ids):
input_ids_embd = self.wte(input_ids)
return input_ids_embd
embd = Embedding(args)
x_embd = embd(xb)
x_embd.shapetorch.Size([16, 218, 36])Trong phần Embedding, thay vì sử dụng phần Position Embedding như trước, LLAMA2 sử dụng phần “rotary position embedding” mà chúng ta sẽ đề cập ở phần dưới.
Rotary Position Embedding
”
class RotaryPositionEmbedding(nn.Module):
def __init__(self, args:ModelArgs, base = 10000):
super().__init__()
self.rotary_dim = 3
inv_freq = 1.0 / (base ** (torch.arange(0, self.rotary_dim, 2) / self.rotary_dim ))
self.register_buffer("inv_freq", inv_freq)
self.cos_cache = None
self.sin_cache = None
def forward(self, qkv):
seqlen = qkv.shape[1]
# Update cos sin cache
t = torch.arange(seqlen)
freqs = torch.outer(t, self.inv_freq)
self.cos_cache = torch.cos(freqs)
self.sin_cache = torch.sin(freqs)
# Apply rotary qkv
rotary_dim = self.cos_cache.shape[1]
rotary_dim *= 2
q_rot = qkv[:, :, 0, :, :rotary_dim]
q_pass = qkv[:, :, 0, :, rotary_dim:]
k_rot = qkv[:, :, 1, :, :rotary_dim]
k_pass = qkv[:, :, 1, :, rotary_dim:]
# Splits the queries and keys in half
q1, q2 = q_rot.chunk(2, dim=-1)
k1, k2 = k_rot.chunk(2, dim=-1)
c, s = rearrange(self.cos_cache, "t d -> t 1 d"), rearrange(self.sin_cache, "t d -> t 1 d")
# Computes the new keys and queries
q_rot = torch.cat([q1 * c - q2 * s, q1 * s - q2 * c], dim=-1)
k_rot = torch.cat([k1 * c - k2 * s, k1 * s - k2 * c], dim = -1)
return torch.cat(
[
torch.cat([q_rot, q_pass], dim=-1).unsqueeze(2),
torch.cat([k_rot, k_pass], dim=-1).unsqueeze(2),
qkv[:, :, 2:3, :, :]
],
dim=2
)Rotary Position Embedding, là một phiên bản tối ưu hóa của việc Position Embedding thông thường. Thay vì đơn giản là thêm một vector vị trí cho từng từ trong câu, chúng ta thực hiện một phép xoay (rotation) trên các giá trị trong ma trận Query và ma trận Key.
Mục tiêu chính của Rotary Position Embedding là tối ưu hóa tốc độ tính toán. Bằng cách áp dụng phép xoay này, chúng ta giúp mô hình học cách tương tác vị trí một cách hiệu quả hơn và giảm sự phức tạp của tính toán so với việc sử dụng Position Embedding truyền thống bằng vector vị trí.
Đoạn code trên được dựa trên code của Microsoft Phi-1.5. Tôi thấy đoạn code này gọn gàng và dễ hiểu hơn, vì vậy tôi đã sử dụng nó. Tuy nhiên, về bản chất, không có sự khác biệt lớn so với code của LLAMA2.
Trong chương này chúng ta sẽ tạm dừng tại đây. Tôi sẽ chỉ thêm một dòng code mới để thực hiện phép xoay QKV trong class Attention. Còn lại, tôi sẽ giữ nguyên như chương trước. Lý do là vì tôi nghĩ sẽ có nhiều bạn muốn thực sự hiểu toàn bộ mã code ở trên và sẽ cần dành nhiều thời gian để nghiên cứu. Và nếu như vậy, chương này đã là quá dài và nên tạm dừng để họ có thể giải lao và chuyển sang một chương mới vào ngày hôm sau. Tuy nhiên nếu bạn giống tôi, sẵn sàng tiếp tục học kiến thức mới sau khi đã hiểu ý tưởng cơ bản của Rotary Position Embedding, hãy cứ thoải mái mà chuyển sang chương tiếp theo.
class Attention(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
self.rotary_emb = RotaryPositionEmbedding(args)
self.head_dim = args.n_embd // args.n_head
opt_size = args.n_head * self.head_dim
hidden_size = args.n_embd
self.Wqkv = nn.Linear(hidden_size, 3 * opt_size)
self.out_proj = nn.Linear(opt_size, hidden_size)
def forward(self, input_ids_embd_norm):
seq_len = input_ids_embd_norm.shape[1]
qkv = self.Wqkv(input_ids_embd_norm)
qkv = rearrange(qkv, 'b t (three h d) -> b t three h d', three=3, d=self.head_dim)
# New code
# Rotary Query & Key
# -------------------------
qkv = self.rotary_emb(qkv)
# -------------------------
q, k, v = qkv.unbind(2)
softmax_scale = 1.0 / math.sqrt(q.shape[-1])
scores = torch.einsum("bthd, bshd -> bhts", q, k * softmax_scale)
mask = torch.triu(torch.full((seq_len, seq_len), -10000), 1)
scores += mask
attention_weights = torch.softmax(scores, dim=-1)
output = torch.einsum("bhts, bshd -> bthd", attention_weights, v)
output = rearrange(output, "... h d -> ... (h d)")
attn_out = self.out_proj(output)
return attn_out# Normalize
attn_norm = nn.LayerNorm(args.n_embd)
x_embd_norm = attn_norm(x_embd)
attn = Attention(args)
attn_out = attn(x_embd_norm)
# add residual
attn_out += x_embd
attn_out.shapetorch.Size([16, 218, 36])class FeedForward(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
hidden_size = 4 * args.n_embd
self.fc1 = nn.Linear(args.n_embd, hidden_size)
self.fc2 = nn.Linear(hidden_size, args.n_embd)
self.act = nn.ReLU()
def forward(self, attn_out_norm):
hidden_states = self.fc1(attn_out_norm)
hidden_states = self.act(hidden_states)
ffwd_out = self.fc2(hidden_states)
return ffwd_out# Normalize
ffwd_norm = nn.LayerNorm(args.n_embd)
attn_out_norm = ffwd_norm(attn_out)
ffwd = FeedForward(args)
ffwd_out = ffwd(attn_out_norm)
# add residual
ffwd_out += attn_out
ffwd_out.shapetorch.Size([16, 218, 36])class TransfomerBlock(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
self.attention_norm = nn.LayerNorm(args.n_embd)
self.ffwd_norm = nn.LayerNorm(args.n_embd)
self.attn = Attention(args)
self.ffwd = FeedForward(args)
def forward(self, input_embd):
attn_out = input_embd + self.attn(self.attention_norm(input_embd))
ffwd_out = attn_out + self.ffwd(self.ffwd_norm(attn_out))
return ffwd_outt_block = TransfomerBlock(args)
ffwd_out = t_block(x_embd)
ffwd_out.shapetorch.Size([16, 218, 36])class TransformerHead(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
self.norm = nn.LayerNorm(args.n_embd)
self.linear = nn.Linear(args.n_embd, args.vocab_size)
def forward(self, ffwd_out):
ffwd_out_norm = self.norm(ffwd_out)
logits = self.linear(ffwd_out_norm)
return logits
t_head = TransformerHead(args)
logits = t_head(ffwd_out)
logits.shapetorch.Size([16, 218, 50257])class TransformerSequential(nn.Module):
def __init__(self, args:ModelArgs):
super().__init__()
modules = [Embedding(args)]
modules += [TransfomerBlock(args) for _ in range(args.n_layer)]
modules.append(TransformerHead(args))
self.layers = nn.Sequential(*modules)
def forward(self, input_ids):
logits = self.layers(input_ids)
return logitsmodel = TransformerSequential(args)
logits = model(xb)
logits.shapetorch.Size([16, 218, 50257])class TransformerLoss(nn.Module):
def __init__(self):
super().__init__()
self.loss_fct = nn.CrossEntropyLoss()
def forward(self, logits, labels):
logits = logits.view(-1, logits.shape[-1])
labels = labels.view(-1)
loss = self.loss_fct(logits, labels)
return losst_loss = TransformerLoss()
loss = t_loss(logits, yb)
losstensor(10.7649, grad_fn=<NllLossBackward0>)data = tokenized_dataset['input_ids']
sequence_len = data.size(1) - 1
vocab_size = tokenizer.vocab_size
args = ModelArgs(sequence_len, vocab_size)
xb, yb = get_batch(data, args.batch_size)
model = TransformerSequential(args)
logits = model(xb)
t_loss = TransformerLoss()
loss = t_loss(logits, yb)
losstensor(11.2564, grad_fn=<NllLossBackward0>)